Answer all of your RFPs really fast with the RFP Monster

Update
I found out my project was featured in Wired magazine in October! Check out the article here.
Introduction
In our last company Hackathon, my team won second place where the reward was a bunch of pats on the back and a little bit of prize money. This was not the first hackathon I’ve done nor was it the first where my team placed in the top three but I’m proud enough of this one to write about it. It was the first time I led our team on everything from software development to the business presentation. Our project was called the RFP Monster and our vision was this:
“Win more deals by enabling our sales force to answer lots of questions better and faster. That’s it.”
What is an RFP?
RFP stands for ‘Request for Proposal’. They are questionnaires that companies send out to prospective vendors when they’re considering buying software or a service. At a company that sells fairly sophisticated Machine Learning software, answering these is a not a trivial task. I’ve seen documents containing upwards of 200 questions (seriously) and answering them thoroughly requires knowledge of pretty much every part of our company. Besides the nitty gritty details of how it handles machine learning problems, there are often questions about our architecture, security, downtime, and pricing among other topics. They are annoying hoops jump through and answering them well involves people from a bunch of different departments. I can’t imagine who on the customer side would actually read through all of the responses. Yet they are a necessary evil. Many prospects won’t talk to you unless you fill them out.
The Solution
The obvious answer to this problem for anyone familiar with Large Language Models (LLMs) and vector databases is to use RAG which stands for Retrieval Augmented Generation. The idea is that you take all of your relevant documentation, split them into chunks, and shove them into special type of database that can encode text data. Then for a given question, you encode it, retrieve the chunks of text from the database that are most similar to it, and shove the chunks in your prompt as context to help something like chatGPT generate an answer. With packages like langchain and local open source vector databases like FAISS, this was pretty easy to build. To make our answers a little more specialized, we loaded about 600 pages of our platform documentation, our security policies, and a few RFPs we had answered before.
This alone would not have placed us in the hackathon though. By this time, RAG was a familiar method in the company. To take it a step further, I wanted to figure out a way to interlink RAG answers with traditional machine learning. To do this, our team took an RFP with about 150 questions, generated 150 answers. And then hand labeled them as Correct or one of multiple classes of Incorrect, such as “Insufficient Knowledge Base” or “Hallucination”. We then trained a classifier (we called this an audit model) on the labeled responses and used it to assign a confidence score for any answers generated by the RFP Monster. To take it a step further, we set up a configuration in our web app that would re-query the LLM in different ways if the confidence score was low enough. The diagram I made for this work is below:
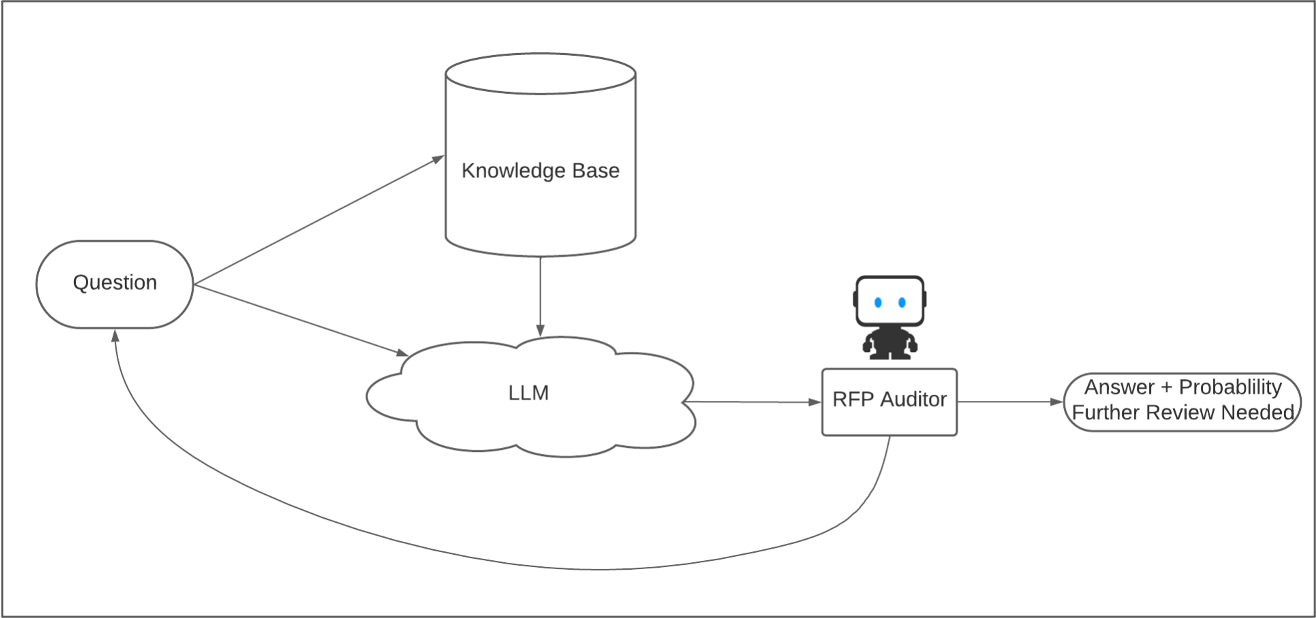
We had a couple other bells and whistles in there too, like a way to submit new question answer pairs to our vector database and a system to give feedback and retrain our audit model.
Post Hackathon
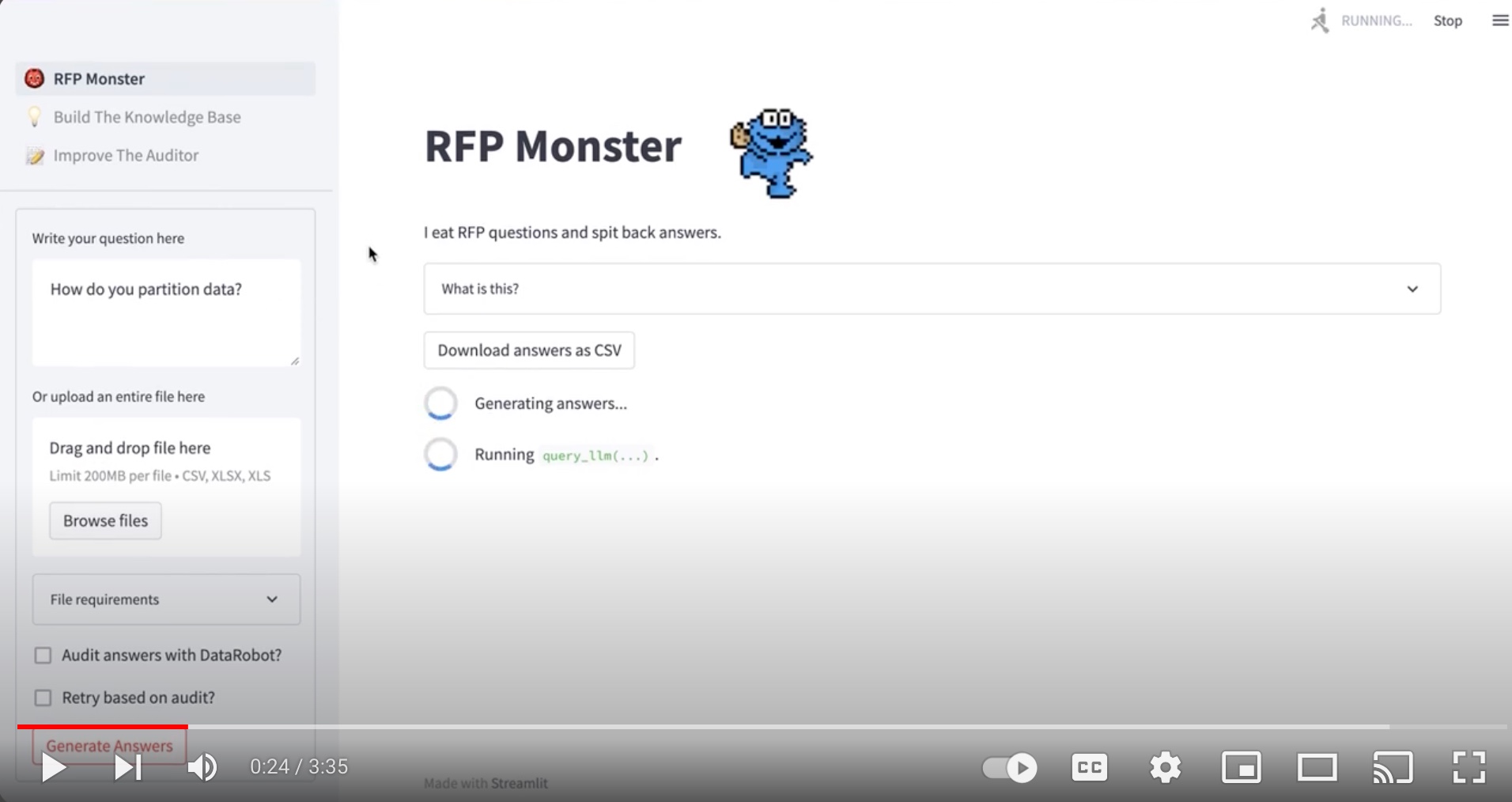
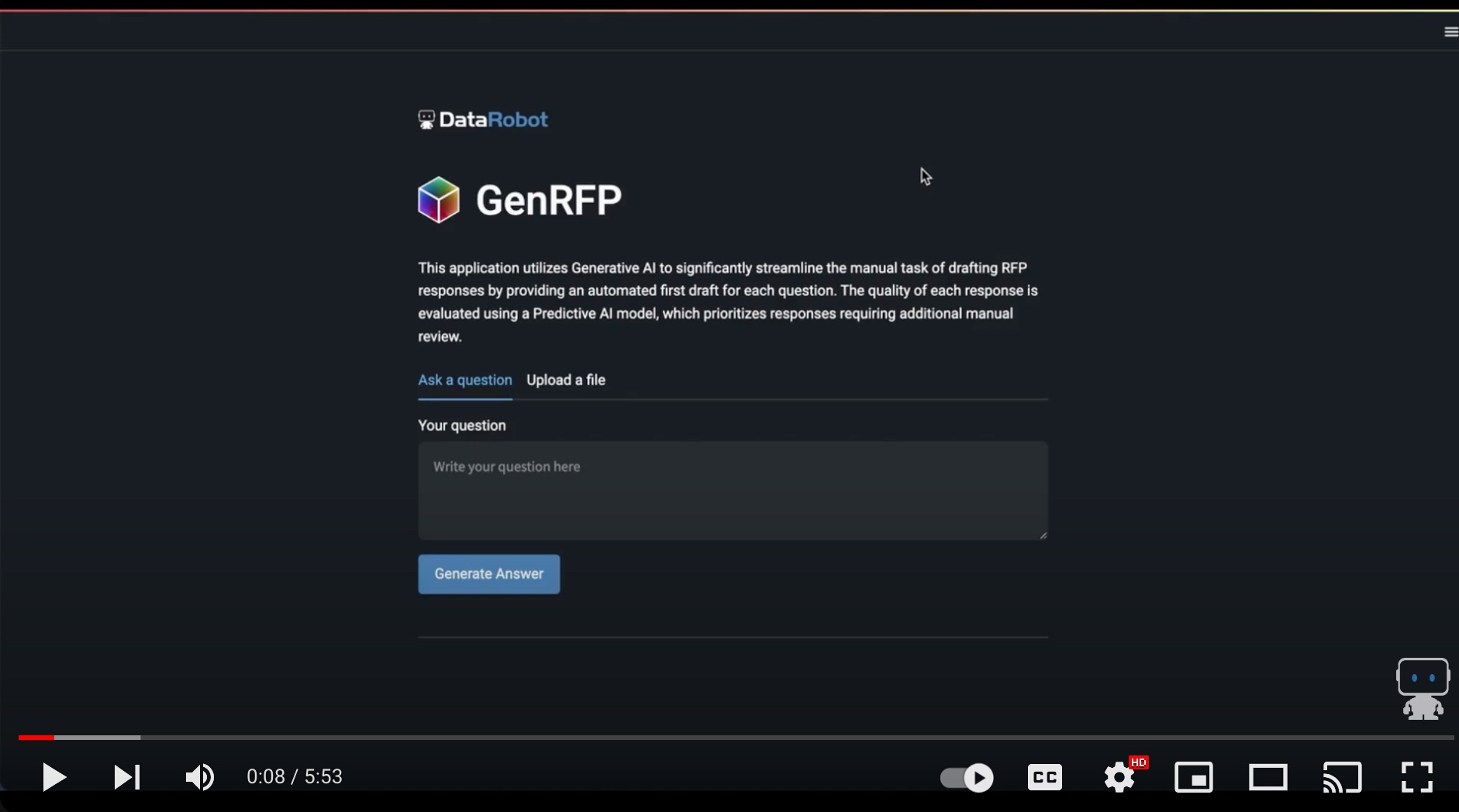
My company marketed our project pretty heavily since we presented. They even made me take away the cookie monster stuff and make a more professional demo video of it, which is on the DataRobot Youtube Channel. You can watch both and tell me which one you like better.
RFP Monster (My Hackathon Video)
GenAI and Predictive AI Demo (The professional looking one)
Credits
Cynthia did a lot of the hand labeling for our audit model and Kyle implemented a neat re-querying strategy. A special shout out to John who asked to join my team as an intern and did a bunch of backend work with our vector database and alternative LLMs. Thanks teammates!